
因為我在現場找不到好角度來拍照,就沒有拍任何照片了。但如果想要知道D4SG和個別小組在這場發表會的資訊,可以在這裡找到: https://d4sg.org/events/d4sg-fellowship-2023-unveiling-party/
以下我就對各個組別我覺得有趣的地方來說一下心得:

1. 你真的不是一個人!孤獨老不孤獨
這個case其實是由清華大學統計所的同學來執行的,我相信是統計實習的case。總之他們在分析其實遇到最大的狀況就是新舊系統資料不一的,在清理資料就是個大麻煩了。然而這一組別為了繞過資料清理,他們就把所有資料變成字串,進而利用語言模型(Bert)來做孤老死的預測。
但是他們為了解釋個別變數對於孤老死的影響,所以之後又做了logisitic regression來解釋。這邊做法我認為可以再進一步,例如:
- 用Bert來做資料清理?
- 用logisitic regression來對Bert做model distillation?

2. 請回答1966
1966為政府長照專線,1999為市民服務電話
這組前面做了1966的EDA,可以很簡單易懂的方式來看目前的1966狀況如何。再來就是利用文字探勘的方式,來找尋通話15秒內,最有可能是怎樣的問題,進而加速轉接電話的速度。其中他們所使用的方式為NMF的topic model。之後他們為了讓席次利用最大化,所以引進了erlang c模型。最後做了1966戰情室的dashborad。
其中他們也為了找到連續型和離散型的資料之間的關聯性,所以使用了point-biseries correlation來解決問題。
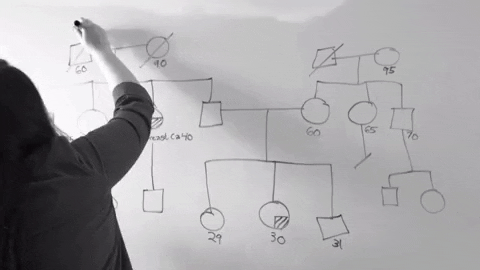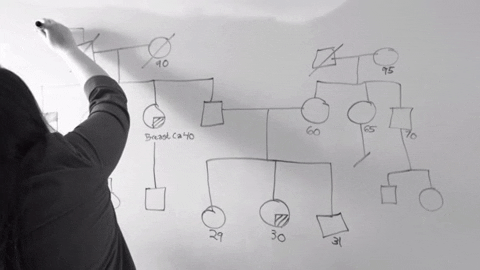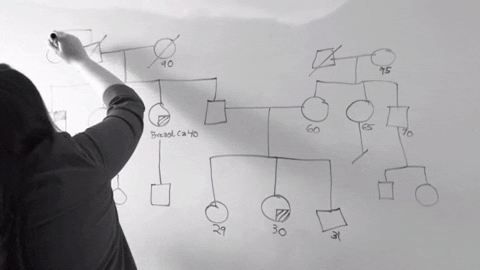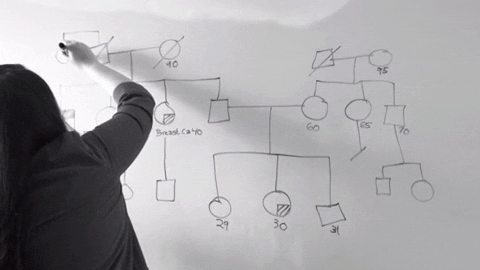
3. 兒少保護高效能網絡合作
這組是我最不懂的組別,總之就是為了讓家暴的個案單位,從被害人本身變成整個家庭,因此嘗試導入知識本體的概念進入家暴防治系統。同時,為了讓整個資料收集更加格式化,並且也為了在政府的大計畫下來之前的中間過度系統,他們使用了word和excel建立了資料收集表格和小型資料庫。

總結
我認為這是個很具有意義的活動,活動本身就是利用data science來幫助社會以及公部門來解決問題。同時,不同的成員也會有不同的火花,進而讓更多的創意和想法來協助整個社會。
除此之外,有些想法我有興趣深入了解一下,其中應該會做成文章介紹的是:
- model distillation
- erlang c
- point-biseries correlation
而可能會有project的是:
- Bert classification
- point-biseries correlation
- topic model with NMF


![[ 筆記 ] 後端基礎 - PHP](https://mtr04-note.coderbridge.io/2020/07/30/about-php/?utm_source=coderbridge-io&utm_medium=blog_related_post_img&utm_campaign=ChengChingLin_[ 筆記 ] 後端基礎 - PHP_@krebikshaw_https://static.coderbridge.com/img/krebikshaw/5a69960d129648c6a2cd6ebdbd7d2889.jpg)


